

Internet sta Marcendo “È già Andato Perduto Troppo”e Il Collante che Tiene Insieme la Conoscenza dell’Umanità si sta Sciogliendo
Il grande pubblico non si rende neanche lontanamente conto di cosa si cela dietro le quinte di una piattaforma come internet che ognuno da per scontato apra le porte del paradiso e dell’inferno con un semplice click sulla tastiera.
In un mondo accessibile a tutti come quello della rete, ognuno si illude di poter accedere ad una libera conoscenza che scardini i mille inganni che vengono posti all’attenzione di una platea ignara che nel momento in cui si posiziona davanti ad un Desktop o di un iPhone, ha una illimitata quantità di dati la cui funzione è quella di deviare la percezione di una realtà per come dovrebbe essere conosciuta.
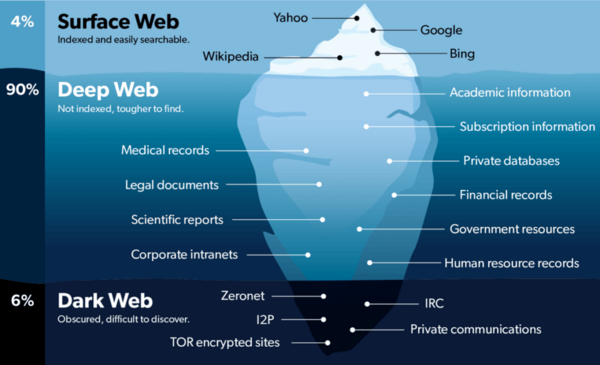
Noi stessi dobbiamo sempre più accedere al DeepWeb svincolato da ogni regola che per intenderci contiene il 96% su tutto quanto circola nel mondo della rete e che vede il 4% rimasto nella mani di persone che oggettivamente pensano di sapere tutto, ma che in realtà risultano essere semplicemente degli analfabeti digitali in balia di un mostro invisibile che si muove attraverso algoritmi che scandiscono la vita e la morte di coloro che ad essa delegano la propria connessione col mondo.
Invito tutti a leggere con attenzione questo servizio che anche se un po’ impegnativo da un idea di che cosa significhi attualmente il web e come sono cambiate le cose dalle sue origini a oggi, la cui libertà anche qui gli sia stata negata per essere sempre più in sintonia con il mondo in cui viviamo.
Toba60
Questo lavoro comporta tempo e denaro e senza fondi non possiamo dare seguito ad un progetto che dura ormai da anni, sotto c’è un logo dove potete contribuire a dare continuità a qualcosa che pochi portali in Italia e nel mondo offrono per qualità e affidabilità di contenuti unici nel loro genere.

Internet sta Marcendo
Sessant’anni fa il futurista Arthur C. Clarke osservò che qualsiasi tecnologia sufficientemente avanzata è indistinguibile dalla magia. Internet, il modo in cui comunichiamo tra di noi e conserviamo insieme i prodotti intellettuali della civiltà umana, si adatta bene all’osservazione di Clarke. Per dirla con le parole di Steve Jobs, “funziona e basta“, con la stessa facilità con cui si fa clic, si tocca o si parla. E, in linea con le vicissitudini della magia, quando Internet non funziona, le ragioni sono in genere così arcane che le spiegazioni sono utili quanto il tentativo di smontare un incantesimo fallito.

Alla base delle nostre vaste e apparentemente semplici reti digitali ci sono tecnologie che, se non fossero già state inventate, probabilmente non si svilupperebbero più allo stesso modo. Sono artefatti di una circostanza molto particolare ed è improbabile che in una linea temporale alternativa sarebbero state progettate allo stesso modo.
L’architettura distinta di Internet è nata da un vincolo e da una libertà distinti: In primo luogo, i suoi progettisti dalla mentalità accademica non avevano o non si aspettavano di raccogliere ingenti capitali per costruire la rete; in secondo luogo, non volevano o non si aspettavano di guadagnare dalla loro invenzione.
I creatori di Internet non avevano quindi i soldi per creare una rete centralizzata uniforme come, ad esempio, FedEx ha metabolizzato un esborso di decine di milioni di dollari per distribuire aerei, camion, persone e cassette di consegna in livrea, creando un unico sistema di consegna da punto a punto. Invece, si sono accontentati dell’equivalente di regole su come unire le reti esistenti.
Piuttosto che una singola rete centralizzata, sul modello del sistema telefonico tradizionale, gestita da un governo o da alcune grandi aziende di servizi pubblici, Internet è stata progettata per consentire a qualsiasi dispositivo, ovunque, di interoperare con qualsiasi altro dispositivo, permettendo a qualsiasi fornitore di portare la propria capacità di rete al gruppo in crescita. Poiché i creatori della rete non intendevano monetizzare, e tanto meno monopolizzare, nulla di tutto ciò, la chiave era che i contenuti desiderabili venissero forniti naturalmente dagli utenti della rete, alcuni dei quali avrebbero agito come produttori di contenuti o host, creando punti di ritrovo per gli altri.
A differenza delle reti proprietarie in breve ascesa, come CompuServe, AOL e Prodigy, il contenuto e la rete sarebbero stati separati. In effetti, Internet non aveva e non ha un menu principale, né un amministratore delegato, né un’offerta pubblica di azioni, né un’organizzazione formale. Ci sono solo ingegneri che si incontrano di tanto in tanto per perfezionare i protocolli di comunicazione suggeriti, che i produttori di hardware e software e i costruttori di reti sono poi liberi di adottare a loro piacimento.
Internet era quindi una ricetta per la malta, con l’invito a chiunque, e a tutti, di portare i propri mattoni. Tim Berners-Lee raccolse l’invito e inventò i protocolli per il World Wide Web, un’applicazione da eseguire su Internet. Se il vostro computer parlava “web” eseguendo un browser, allora poteva parlare con i server che parlavano anch’essi web, naturalmente noti come siti web. Le pagine dei siti potrebbero contenere collegamenti a ogni sorta di cose che, per definizione, sarebbero a portata di clic e che, in pratica, potrebbero trovarsi su server situati in qualsiasi altra parte del mondo, ospitati da persone o organizzazioni che non solo non sono affiliate alla pagina web di collegamento, ma sono del tutto ignare della sua esistenza. E le stesse pagine web potrebbero essere assemblate da più fonti prima di essere visualizzate come un’unica unità, facilitando l’ascesa di reti pubblicitarie che potrebbero essere chiamate dai siti web per inserire beacon di sorveglianza e annunci al volo, mentre le pagine vengono riunite nel momento in cui qualcuno cerca di visualizzarle.
E come gli stessi progettisti di Internet, Berners-Lee ha regalato i suoi protocolli al mondo gratuitamente, consentendo un progetto che non prevedeva alcuna forma di gestione o controllo centralizzato, poiché non c’era alcun utilizzo da tracciare da parte di una World Wide Web, Inc. ai fini della fatturazione. Il Web, come Internet, è un’allucinazione collettiva, un insieme di sforzi indipendenti uniti da protocolli tecnologici comuni per apparire come un insieme magico e senza soluzione di continuità.
Questa assenza di controllo centrale, o anche di un facile monitoraggio centrale, è stata a lungo celebrata come uno strumento di democrazia di base e di libertà. Non è banale censurare una rete così organica e decentralizzata come Internet. Più di recente, però, si è compreso che queste caratteristiche facilitano i vettori di molestie individuali e di destabilizzazione della società, senza che sia possibile rimuovere o etichettare facilmente le opere dannose che non rientrano nell’ombrello delle principali piattaforme di social media o identificarne rapidamente le fonti. Sebbene entrambe le valutazioni siano efficaci, non tengono conto di una caratteristica fondamentale del web e di Internet distribuiti: I loro progetti creano naturalmente dei vuoti di responsabilità per il mantenimento di contenuti di valore su cui gli altri fanno affidamento. I collegamenti funzionano perfettamente fino a quando non lo fanno. E mentre le controparti tangibili del lavoro online svaniscono, queste lacune rappresentano veri e propri buchi nella conoscenza dell’umanità.

Prima dell’odierno Internet, il modo principale per preservare qualcosa per i secoli era quello di consegnarlo alla scrittura – prima su pietra, poi su pergamena, poi su papiro, poi su carta priva di acidi da 20 libbre, poi su un lettore di nastri, su un floppy disk o su un disco rigido – e di conservare il risultato in un tempio o in una biblioteca: un edificio progettato per proteggerlo da marciume, furto, guerra e disastri naturali. Questo approccio ha facilitato la conservazione di alcuni materiali per migliaia di anni. Idealmente, ci sarebbero più copie identiche conservate in più biblioteche, in modo che il fallimento di un deposito non estingua la conoscenza al suo interno. E nei rari casi in cui un documento venisse alterato di nascosto, potrebbe essere confrontato con le copie conservate altrove per individuare e correggere la modifica.
Questi edifici non funzionavano da soli e non erano semplici magazzini. Il personale era composto da ecclesiastici e poi da bibliotecari, che promuovevano la cultura della conservazione e le sue numerose pratiche elaborate, in modo da salvaguardare i documenti preziosi e renderli accessibili su larga scala: certamente fisicamente e, cosa altrettanto importante, attraverso un’accurata indicizzazione, in modo che una mente curiosa potesse essere abbinata a tutto ciò che la biblioteca possedeva per soddisfare tale sete. (Come ha sottolineato Jorge Luis Borges, una biblioteca senza indice diventa paradossalmente meno informativa man mano che cresce).
All’alba dell’era di Internet, 25 anni fa, sembrava che la rete avrebbe apportato immensi miglioramenti e forse un po’ di sollievo al lungo lavoro di questi amministratori. L’eccentricità del design di Internet e del web era l’apoteosi della garanzia che il perfetto non sarebbe stato nemico del buono. Invece di un attento sistema di designazione del sapere “importante”, distinto dalla poltiglia quotidiana, e dell’importazione di tale sapere nelle istituzioni e nelle culture della conservazione e dell’accesso permanenti (le biblioteche), c’era solo il web infinitamente variegato, con i siti web di riferimento canonici, come quelli per i documenti accademici e gli articoli di giornale, giustapposti ai PDF, ai blog e ai post dei social media ospitati qua e là.
Studenti intraprendenti hanno progettato web crawler per seguire e registrare automaticamente ogni singolo link che riuscivano a trovare, e poi seguire ogni link alla fine di quel link, per poi costruire una concordanza che permettesse alle persone di cercare in un insieme senza soluzione di continuità, creando motori di ricerca che restituissero i primi 10 risultati per una parola o una frase tra, oggi, più di 100 trilioni di pagine possibili. Come dice Google, “il web è come una biblioteca in continua crescita con miliardi di libri e nessun sistema di archiviazione centrale”.
Ho appena citato il sito web aziendale di Google e ho usato un collegamento ipertestuale in modo che possiate vedere la mia fonte. La fonte è il collante che tiene insieme la conoscenza dell’umanità. È ciò che permette di saperne di più su ciò che è solo brevemente menzionato in un articolo come questo, e ad altri di ricontrollare i fatti come li ho rappresentati. Il link che ho usato punta a https://www.google.com/search/howsearchworks/crawling-indexing/. Supponiamo che Google cambi il contenuto di quella pagina o riorganizzi il suo sito web in qualsiasi momento tra il momento in cui sto scrivendo questo articolo e quello in cui lo state leggendo, eliminandola completamente. Cambiare ciò che c’è sarebbe un esempio di deriva dei contenuti; eliminarli del tutto è noto come link rot.
È emerso che la rotazione dei link e la deriva dei contenuti sono endemiche del web, il che non sorprende e al tempo stesso è molto rischioso per una biblioteca che ha “miliardi di libri e nessun sistema di archiviazione centrale“. Immaginate se le biblioteche non esistessero e ci fosse solo una “sharing economy” per i libri fisici: Le persone potrebbero registrare i libri che hanno in casa e gli altri che li desiderano potrebbero visitarli e consultarli. Non c’è da stupirsi che un sistema del genere possa cadere in disuso, con i libri che non si trovano più dove erano stati pubblicizzati – soprattutto se qualcuno ha segnalato che un libro si trovava a casa di qualcun altro nel 2015, e poi un lettore interessato ha visto quel rapporto del 2015 nel 2021 e ha cercato di visitare la casa originale menzionata come in possesso del libro. Questo è ciò che abbiamo ora sul web.
Che si tratti di un’umile casa o di un enorme edificio governativo, i contenuti possono fallire. Ad esempio, il Presidente Barack Obama ha firmato l’Affordable Care Act nella primavera del 2010. Nell’autunno del 2013, i repubblicani del Congresso hanno bloccato i finanziamenti governativi giornalieri nel tentativo di bloccare l’Obamacare. Le agenzie federali, obbligate a cessare tutte le attività tranne quelle essenziali, hanno staccato la spina ai siti web di tutto il governo degli Stati Uniti, compreso l’accesso a migliaia, forse milioni, di documenti ufficiali del governo, sia attuali che archiviati, e naturalmente pochissimi che avessero a che fare con l’Obamacare. Come la notte segue il giorno, ogni singolo link che punta ai documenti e ai siti interessati non funziona più. Ecco il sito web della NASA dell’epoca:

Nel 2010, il giudice Samuel Alito ha scritto un’opinione concorrente in un caso sottoposto alla Corte Suprema e la sua opinione rimandava a un sito web come parte della spiegazione del suo ragionamento. Poco dopo la pubblicazione del parere, chi seguiva il link non vedeva quello che Alito aveva in mente quando aveva scritto il parere. Al contrario, avrebbe trovato questo messaggio: “Non siete contenti di non aver citato questa pagina web… Se lo aveste fatto, come ha fatto il giudice Alito, il contenuto originale sarebbe scomparso da tempo e qualcun altro avrebbe potuto acquistare il dominio per fare un commento sulla caducità delle informazioni collegate nell’era di Internet”.
Ispirati da casi come questi, io e alcuni colleghi ci siamo uniti a coloro che indagavano sulla portata del link rot nel 2014 e di nuovo la scorsa primavera.
Il primo studio, condotto con Kendra Albert e Larry Lessig, si è concentrato su documenti destinati a durare indefinitamente: link all’interno di articoli scientifici, come quelli presenti nella Harvard Law Review, e opinioni giudiziarie della Corte Suprema. Abbiamo scoperto che il 50% dei link incorporati nelle opinioni della Corte dal 1996, anno in cui è stato utilizzato il primo collegamento ipertestuale, non funzionava più. E il 75% dei link presenti nella Harvard Law Review non funzionava più.
Si tende a trascurare la decadenza del web moderno, mentre in realtà questi numeri sono straordinari: rappresentano una rottura completa della catena di custodia dei fatti. Le biblioteche esistono e contengono ancora libri, ma non gestiscono un’enorme percentuale delle informazioni a cui le persone si collegano, anche all’interno di documenti formali e legali. Nessuno lo fa. La flessibilità del web – la caratteristica stessa che lo fa funzionare, che gli ha permesso di eclissare CompuServe e altre reti organizzate a livello centrale distoglie la responsabilità di questa funzione sociale fondamentale.
Il problema non riguarda solo gli articoli accademici e le opinioni giudiziarie. Con John Bowers e Clare Stanton, e la gentile collaborazione del New York Times, ho potuto analizzare circa 2 milioni di link rivolti all’esterno presenti negli articoli del sito nytimes.com dalla sua nascita nel 1996. Abbiamo scoperto che il 25% dei deep link è marcito. (I link profondi sono link a contenuti specifici – pensate a theatlantic.com/article, invece di theatlantic.com). Più l’articolo è vecchio, meno è probabile che i link funzionino. Se si risale al 1998, il 72% dei link è morto. Complessivamente, più della metà di tutti gli articoli del New York Times che contengono link profondi ha almeno un link marcio.
I nostri studi sono in linea con altri. Già nel 2001, un team dell’Università di Princeton ha studiato la persistenza dei riferimenti web negli articoli scientifici, scoprendo che il numero grezzo di URL contenuti negli articoli accademici era in aumento, ma che molti dei collegamenti erano interrotti, compreso il 53% di quelli presenti negli articoli che avevano raccolto a partire dal 1994. Tredici anni dopo, sei ricercatori hanno creato un set di dati di oltre 3,5 milioni di articoli scientifici su scienza, tecnologia e medicina e hanno stabilito che uno su cinque non punta più alla fonte originariamente prevista. Nel 2016, un’analisi con lo stesso set di dati ha rilevato che il 75% di tutti i riferimenti era andato alla deriva.
Naturalmente, c’è un problema di permanenza molto correlato a gran parte di ciò che si trova online. Le persone comunicano in modi che sembrano effimeri e abbassano di conseguenza la guardia, per poi scoprire che un commento su Facebook può rimanere per sempre. Il risultato è il peggiore dei due mondi: alcune informazioni rimangono quando non dovrebbero, mentre altre svaniscono quando dovrebbero rimanere.
10000 + collegamenti al web oscuro e profondo funzionanti. (Fare molta attenzione!) (In Inglese)
10000-Working-Dark-and-Deep-Web-Links-2020-Thousands-of-Working-Deep-Web-Links.-Rarsa-Amlas-Z-Library_organizedFinora, l’ascesa del web ha portato a fonti di informazione citate di routine che non fanno parte di sistemi più formali; le voci di un blog o i documenti di lavoro inseriti casualmente a un particolare indirizzo web non hanno equivalenti nell’era pre-internet. Ma sicuramente qualsiasi cosa che valga davvero la pena di essere conservata per sempre verrebbe comunque pubblicata come libro o articolo in una rivista scientifica, rendendola accessibile alle biblioteche di oggi e conservabile allo stesso modo di prima? Ahimè, no.
Poiché le informazioni sono così facilmente reperibili online, gli incentivi alla creazione di copie cartacee e alla loro archiviazione nei modi tradizionali sono diminuiti lentamente all’inizio, per poi crollare. Un tempo le copie cartacee erano considerate originali, e qualsiasi complemento digitale era visto come un bonus. Oggi, però, sia gli editori che i consumatori – e le biblioteche che agiscono a lungo termine per conto dei loro clienti – considerano il digitale come il veicolo principale per l’accesso, e le copie cartacee sono deprezzate.
Dal mio punto di vista di professore di diritto, ho visto le ultime persone pronte a spegnere le luci alla fine della festa: i redattori delle riviste accademiche di diritto. Uno dei riti di passaggio più stucchevoli per gli studenti di legge che si iscrivono è quello di “subcitare”, cioè di controllare le citazioni all’interno di una ricerca in corso per assicurarsi che siano nella forma esigente e bizantina richiesta dagli standard di citazione legale e, più direttamente, per assicurarsi che la fonte stessa esista e dica ciò che l’autore della citazione dice. (In un numero piuttosto allarmante di casi, non è così, e questo è un buon motivo per intraprendere l’esercizio di sottocitazione).
La prassi originaria, ad esempio per la Harvard Law Review, era quella di richiedere a uno studente subcitante di mettere gli occhi su una copia cartacea originale della fonte citata, come uno statuto o un parere giudiziario. La Biblioteca di Giurisprudenza di Harvard, a sua volta, si sforzava di conservare una copia fisica di ogni cosa, cioè di ogni legge e caso di ogni dove, proprio a questo scopo. Da allora la Law Review si è attenuata, permettendo alle immagini digitali dei testi stampati di essere sufficienti, e questo non è del tutto sgradito: Si è scoperto che la legge fisica (distinta dalle leggi della fisica) occupa molto spazio e la Harvard Law School stava inviando sempre più libri a un deposito remoto, da recuperare faticosamente quando necessario.
Qualche anno fa ho contribuito a guidare uno sforzo di digitalizzazione di tutta quella carta, sia come immagini che come testo ricercabile – più di 40.000 volumi che comprendono più di 40 milioni di pagine – che ha completato la scansione di quasi tutti i casi pubblicati di ogni Stato dal momento della nascita di quello Stato fino alla fine del 2018. (I libri scansionati sono stati inviati a una miniera di calcare abbandonata nel Kentucky, come copertura contro una sorta di apocalisse digitale o addirittura fisica).
Una particolarità ci ha permesso di effettuare questa scansione e di trattare la longevità del risultato con la stessa serietà con cui trattiamo qualsiasi materiale stampato: La giurisprudenza americana non è coperta da copyright, perché è il prodotto dei giudici. (In effetti, qualsiasi opera del governo degli Stati Uniti deve essere di pubblico dominio per legge ). Ma la biblioteca della Harvard Law School non raccoglie più le edizioni stampate da cui effettuare la scansione: è troppo costoso. E altri materiali stampati sono essenzialmente intrappolati sulla carta fino a quando la legge sul copyright non sarà perfezionata per tener conto delle circostanze digitali.
In questo vuoto è entrato il materiale nato in digitale, offerto dagli stessi editori che prima vendevano su carta stampata. Ma c’è un problema: Queste manifestazioni digitali di materiale ufficialmente sancito hanno un asterisco accanto alla loro permanenza. Che sia un privato o una biblioteca ad acquistarli, l’acquirente in genere compra il semplice accesso al materiale per un certo periodo di tempo, senza la possibilità di trasferire l’opera nel contenitore scelto dall’acquirente stesso. Questo è vero per molte riviste scientifiche pubblicate in commercio, per le quali “abbonamento” non significa più una consegna regolare di volumi cartacei che, se annullata, significa semplicemente che non ne arriveranno altri. L’abbonamento è invece un accesso continuo all’intero corpus di riviste ospitate dagli editori stessi. Se l’abbonamento viene interrotto, l’intera opera diventa inaccessibile.
In questi scenari le biblioteche non sono più custodi per l’età di qualsiasi cosa, sia essa tangibile o intangibile, ma piuttosto dei collettori di fondi per pagare l’accesso fugace alla conoscenza altrove.
Allo stesso modo, oggi i libri vengono spesso acquistati sui Kindle, che sono gli Hotel California dei dispositivi digitali: Entrano ma non possono essere estratti, se non da Amazon. I libri acquistati possono essere involontariamente “zappati” da Amazon, che è noto per averlo fatto, rimborsando il prezzo di acquisto originale. Ad esempio, 10 anni fa un libraio di terze parti ha offerto un noto libro in formato Kindle su Amazon a 99 centesimi a copia, pensando erroneamente che non fosse più sotto copyright. Una volta constatato l’errore, Amazon, in preda al panico, si è recato su tutti i Kindle che avevano scaricato il libro e lo ha cancellato. Il libro era, giustamente, 1984 di George Orwell. (Non avete 1984. In realtà, non avete mai avuto 1984. Non esiste un libro come 1984).
All’epoca, l’incidente fu considerato suggestivo ma non veramente preoccupante; dopo tutto, erano disponibili molte copie fisiche di 1984. Oggi che l’acquisto di libri, sia individuale che in biblioteca, si sposta dal fisico al digitale, la de-piattaforma di un libro Kindle, anche se retroattiva, può avere un peso molto maggiore.
La cancellazione non è l’unico problema. Non solo le informazioni possono essere rimosse, ma possono anche essere modificate. Prima dell’avvento di Internet, sarebbe stato inutile cercare di cambiare il contenuto di un libro dopo che era stato pubblicato da tempo. I bibliotecari non vedono di buon occhio il tentativo di strappare o modificare alcune pagine di un libro “sbagliato”. L’approssimazione più vicina all’editing post-hoc sarebbe stata quella di influenzare il contenuto di un’edizione successiva.
Gli ebook non hanno queste limitazioni, sia per la facilità con cui si possono creare nuove edizioni, sia per la semplicità con cui si possono aggiornare a posteriori le edizioni esistenti. Consideriamo l’esperienza di Philip Howard, che nel 2010 si è seduto a leggere un’edizione stampata di Guerra e pace. A metà della lettura del tomo, ha acquistato un’edizione elettronica a 99 centesimi per il suo e-reader Nook:
Mentre leggevo, mi sono imbattuto in questa frase: “Era come se fosse stata accesa una luce in una lanterna intagliata e dipinta…”. Pensando che si trattasse semplicemente di un difetto del software, ignorai la parola invadente e continuai a leggere. Alcune pagine più tardi ho incontrato di nuovo la parola disonesta. Al terzo incontro ho deciso di recuperare il mio libro con copertina rigida e di trovare il testo originale (o meglio, la traduzione).
Per la frase sopra riportata ho scoperto questa traduzione autentica: “Era come se una luce si fosse accesa in una lanterna intagliata e dipinta…”.Per la frase sopra riportata ho scoperto questa traduzione autentica: “Era come se una luce si fosse accesa in una lanterna intagliata e dipinta…”.
Una ricerca su questa versione Nook del libro lo ha confermato: Ogni volta che la parola kindle è stata sostituita da nook, forse nel tentativo di alterare una versione Kindle del libro precedentemente realizzata per l’uso di Nook. Ecco alcune schermate che ho scattato in quel momento:


È solo questione di tempo prima che la malleabilità retroattiva di queste forme di pubblicazione diventi una nuova area di pressione e regolamentazione per la censura dei contenuti. Se un libro contiene un passaggio che qualcuno ritiene diffamatorio, la persona danneggiata può intentare una causa – e ricevere un risarcimento in denaro se ha ragione. Raramente viene messa in discussione l’esistenza stessa del libro, se non altro per la difficoltà di rimettere il gatto nel sacco dopo la pubblicazione.
Ora è molto più facile chiedere un perfezionamento o una vera e propria modifica della frase o del paragrafo incriminato. Finché questi rimedi non sono più fantasiosi, i termini di un accordo possono includerli, così come la promessa di non pubblicizzare l’avvenuta modifica. Non è necessario intentare una causa; è sufficiente una richiesta, pubblica o privata, non basata su una rivendicazione legale, ma semplicemente sull’indignazione e sulla potenziale pubblicità. Rileggere un vecchio libro preferito su Kindle potrebbe quindi diventare una versione leggermente (anche se momentaneamente) modificata di quel vecchio libro, con la sola sensazione fastidiosa che non sia proprio come lo si ricorda.
Non è un’ipotesi. Questo mese l’autrice di bestseller Elin Hilderbrand ha pubblicato un nuovo romanzo. Il romanzo, ampiamente elogiato dalla critica, include un frammento di dialogo in cui un personaggio fa una battuta ironica a un altro sul fatto di passare l’estate in una soffitta a Nantucket, “come Anna Frank”. Alcuni lettori si sono espressi sui social media criticando questo momento tra i personaggi come antisemita. L’autrice ha cercato di spiegare l’uso dell’analogia da parte del personaggio, prima di porgere le sue scuse e dire di aver chiesto al suo editore di rimuovere immediatamente il passaggio dalle versioni digitali del libro.
Le modifiche tecniche e tipografiche apportate agli ebook dopo la loro pubblicazione sono tali che una casa editrice stessa potrebbe non avere nemmeno una semplice contabilità di quante volte essa stessa, o uno dei suoi autori, sia stata importunata a modificare ciò che è già stato pubblicato. Quasi 25 anni fa ho aiutato Wendy Seltzer a creare un sito, ora chiamato Lumen, che tiene traccia delle richieste di elisioni da parte di istituzioni che vanno dall ‘Università della California all’Internet Archive a Wikipedia, Twitter e Google, spesso per presunte violazioni del copyright riscontrate cliccando sui link pubblicati. Lumen permette quindi di saperne di più su ciò che manca o viene modificato, ad esempio, da una ricerca web di Google, a causa di richieste o esigenze esterne.
Ad esempio, grazie alla registrazione da parte del sito sia delle cancellazioni che della fonte e del testo delle richieste di rimozione, il professore di diritto Eugene Volokh è stato in grado di identificare un certo numero di richieste di rimozione effettuate con documentazione fraudolenta– quasi 200 delle 700 “ordinanze giudiziarie” presentate a Google che ha esaminato si sono rivelate apparentemente photoshoppate di sana pianta. Il procuratore generale del Texas ha poi citato in giudizio un’azienda per aver presentato abitualmente a Google questi ordini giudiziari falsificati allo scopo di forzare la rimozione dei contenuti. Il rapporto di Google con Lumen è puramente volontario: YouTube, che come Google ha la società madre Alphabet, non invia attualmente avvisi. Le rimozioni effettuate da altre aziende, come editori di libri e distributori come Amazon, non sono disponibili pubblicamente.

L’ascesa del Kindle evidenzia che anche il concetto di link – un “localizzatore uniforme di risorse”, o URL – è sottoposto a grande stress. Poiché i libri Kindle non vivono sul World Wide Web, non esiste un URL che punti a una pagina o a un passaggio particolare. Lo stesso vale per i contenuti delle applicazioni mobili, che lasciano le persone a scambiarsi screenshot – o, come ha detto Kaitlyn Tiffany di The Atlantic, “i gremlins di Internet” come mezzo per trasmettere i contenuti.
Ecco, per gentile concessione della professoressa di diritto Alexandra Roberts, come un parere del tribunale distrettuale ha indicato un video di TikTok: “Un video di TikTok del maggio 2020 che presenta i peluche reversibili Octopus ha ora oltre 1,1 milioni di like e 7,8 milioni di visualizzazioni. Il video si trova su Girlfriends mood #teeturtle #octopus #cute #verycute #animalcrossing #cutie #girlfriend #mood #inamood #timeofmonth #chocolate #fyp #xyzcba #cbzzyz #t (tiktok.com)”.
Il che ci riporta al fatto che la scrittura a lungo termine, compresi i documenti ufficiali, potrebbe spesso aver bisogno di puntare a fonti non canoniche a breve termine per stabilire ciò che intende dire, e i mezzi per farlo si stanno disintegrando sotto i nostri occhi (o peggio, del tutto inosservati). E anche le fonti canoniche a lungo termine, come i libri e le riviste accademiche, sono in configurazioni fugaci – di solito per supportare modelli di abbonamento digitale che richiedono scarsità che precludono un pronto collegamento a lungo termine, anche quando le loro controparti fisiche evaporano.
Il progetto di preservare e costruire il nostro percorso intellettuale, compresi tutti i suoi meandri e le sue false partenze, è quindi vittima del successo catastrofico della rivoluzione digitale che avrebbe dovuto sostenerlo. Gli strumenti che avrebbero potuto mettere a disposizione di tutti la produzione di conoscenza dell’umanità hanno invece, per ragioni del tutto comprensibili, militato verso un “adesso” in continua evoluzione, dove non è facile citare molte fonti per i posteri e quelle citabili sono fin troppo mutevoli.
Anche in questo caso, lo straordinario successo dell’improbabile ed eccentrica architettura di Internet è dovuto alla saggia decisione di privilegiare il bene rispetto al perfetto e il generale rispetto allo specifico. L’ho chiamato con ammirazione il “principio della procrastinazione“, secondo il quale un progetto di rete elegante non sarebbe stato indebitamente complicato dai tentativi di risolvere ogni possibile problema che si potesse immaginare di materializzare in futuro. Vediamo questo principio all’opera in Wikipedia, dove la proposta iniziale sembrerebbe assurda: “Possiamo generare un’enciclopedia estremamente completa e per lo più affidabile permettendo a chiunque nel mondo di creare una nuova pagina e a chiunque altro nel mondo di passare a rivederla”.
Verrebbe spontaneo chiedersi che cosa potrebbe motivare qualcuno a contribuire in modo costruttivo a una cosa del genere, e quali difese potrebbero esserci contro le modifiche fatte in modo ignorante o in malafede. Se Wikipedia avesse un’attività e un utilizzo sufficienti, qualche venditore da quattro soldi non sarebbe motivato a trasformare ogni articolo in una pubblicità spammosa per un orologio Rolex?
In effetti, Wikipedia soffre di vandalismo e, nel tempo, la comunità che la sostiene ha sviluppato strumenti e pratiche per affrontarlo che non esistevano al momento della creazione di Wikipedia. Se fossero stati implementati troppo presto, gli ostacoli aggiuntivi all’apertura e alla modifica delle pagine avrebbero potuto scoraggiare molti dei contributi che hanno fatto nascere Wikipedia. Il principio di procrastinazione ha dato i suoi frutti.
Allo stesso modo, Tim Berners-Lee, l’inventore del web, non aveva in mente di controllare i nuovi siti web proposti in base a standard di verità, affidabilità o… altro. Le persone potevano costruire e offrire quello che volevano, purché avessero l’hardware e la connettività per installare un server web, e gli altri sarebbero stati liberi di visitare quel sito o di ignorarlo come volevano. Il fatto che i siti web andassero e venissero, e che le singole pagine potessero essere riorganizzate, era una caratteristica, non un difetto. Così come Internet avrebbe potuto essere strutturato come un grande CompuServe, a mediazione centrale, ma non lo è stato, il web avrebbe potuto avere un numero qualsiasi di caratteristiche per assicurare meglio la permanenza e la provenienza. Il progetto Xanadu di Ted Nelson prevedeva tutto questo e molto altro, compresi i “link bidirezionali” che avrebbero avvisato un sito ogni volta che qualcuno avesse scelto di collegarsi ad esso. Ma Xanadu non è mai decollato.
Come sanno i procrastinatori, più tardi non significa mai, e i vantaggi della flessibilità di Internet e del Web – tra cui la possibilità di costruire sopra di essi giardini di applicazioni murati che rifiutano del tutto l’idea di un URL – ora comportano grandi rischi e costi per la più ampia impresa tettonica di, nelle prime parole di Google, “organizzare le informazioni del mondo e renderle universalmente accessibili e utili”.
L’idea di Sergey Brin e Larry Page era nobile, così nobile che affidarla a un’unica azienda, piuttosto che a istituzioni sociali da tempo consolidate, come le biblioteche, non le avrebbe reso giustizia. Infatti, quando i fondatori di Google pubblicarono per la prima volta un documento che descriveva il motore di ricerca che avevano inventato, inclusero un’appendice sulla “pubblicità e le motivazioni miste”, concludendo che “la questione della pubblicità causa abbastanza incentivi misti da rendere cruciale la presenza di un motore di ricerca competitivo che sia trasparente e nel regno accademico”. Nel 2021 non esiste un motore di ricerca competitivo trasparente e accademico. Rendendo l’archiviazione e l’organizzazione delle informazioni una responsabilità di tutti e di nessuno, Internet e il web potrebbero crescere, ampliando l’accesso senza precedenti, ma rendendo tutto ciò fragile anziché robusto in molti casi in cui dipendiamo da esso.

Come risolvere la crisi in cui ci troviamo? Nessuno è più consapevole del problema dell’effimerità di Internet di Brewster Kahle, un tecnologo che nel 1996 ha fondato l’Internet Archive, uno sforzo senza scopo di lucro per preservare la conoscenza dell’umanità, in particolare il web. Brewster aveva sviluppato un precursore del web chiamato WAIS e poi una piattaforma di misurazione del traffico web chiamata Alexa, poi acquistata da Amazon. Quella vendita mise Brewster in condizione di contribuire personalmente a finanziare le operazioni iniziali di Internet Archive, tra cui la Wayback Machine, progettata appositamente per raccogliere, salvare e rendere disponibili le pagine web anche dopo la loro scomparsa. Per farlo, ha scelto più punti di ingresso per iniziare a “scrapare” le pagine – salvandone il contenuto invece di visualizzarle semplicemente in un browser per un momento – e poi ha seguito il maggior numero possibile di link successivi su quelle pagine e sulle pagine collegate a quelle pagine.
Non è una coincidenza che a farsi avanti sia stato un singolo cittadino di grande senso civico come Brewster, anziché le istituzioni esistenti. In parte ciò è dovuto ai potenziali rischi legali che tendono a rallentare o scoraggiare le organizzazioni consolidate. Le implicazioni sul diritto d’autore legate al crawling, all’archiviazione e alla visualizzazione del web sono state all’inizio poco chiare, e in genere tali azioni sono state affidate a soggetti che potevano essere poco esigenti, conservando ciò che scartavano solo per loro stessi; a soggetti commerciali grandi e potenti, come i motori di ricerca, i cui imperativi commerciali rendevano centrale per il loro funzionamento la visualizzazione solo delle pagine più recenti e attive; oppure a individui orientati alla tecnologia con una mentalità da start-up e poco da perdere. Un esempio di quest’ultimo caso è quello di Clearview AI, in cui un singolo imprenditore avventato ha raccolto miliardi di immagini e tag da siti di social network come Facebook, LinkedIn e Instagram per costruire un database di riconoscimento facciale in grado di identificare quasi tutte le foto o i video di una persona.
Il Deep Web per giornalisti investigativi- Comunicazioni, controsorveglianza, ricerca….( Fare molta attenzione!) (In Inglese)
The-Digital-Journalists-Handbook-Deep-Web-For-Journalists-–-Comms-Counter-Surveillance-Search-Alan-Pearce-Z-Library_organizedAnche Brewster appartiene superficialmente a questa categoria, ma nello spirito degli inventori di Internet e del Web sta facendo ciò che fa perché crede nella virtù del suo lavoro, non nel suo potenziale finanziario. L’approccio di Wayback Machine è quello di salvare il più possibile il più spesso possibile, e in pratica questo significa molte cose ogni tanto. Si tratta di un lavoro vitale, che dovrebbe essere sostenuto molto di più, sia con sovvenzioni governative che con un maggiore sostegno da parte delle fondazioni. (Internet Archive è stato semifinalista per l’iniziativa “100 and Change” della Fondazione MacArthur, che assegna individualmente 100 milioni di dollari a cause meritevoli).
Un approccio complementare per “salvare tutto” attraverso lo scraping indipendente consiste nel fare in modo che chi crea un link ne salvi una copia nel momento in cui viene creato il link. I ricercatori del Berkman Klein Center for Internet & Society, che ho co-fondato, hanno progettato un sistema di questo tipo con un pacchetto open-source chiamato Amberlink. Internet e il web invitano a qualsiasi forma di costruzione aggiuntiva, poiché nessuno approva formalmente le nuove aggiunte. Amberlink può essere eseguito su alcuni server web per fare in modo che ciò che si trova alla fine di un link possa essere catturato quando una pagina web su un server alimentato da Amberlink include per la prima volta quel link. In questo modo, quando si fa clic su un link su un sito sintonizzato su Amber, si ha la possibilità di vedere ciò che il sito ha catturato in quel link, nel caso in cui la destinazione originale non sia più disponibile. (Anche i motori di ricerca come Google hanno questa funzione: spesso si può chiedere di vedere la copia “in cache” di una pagina web collegata da una pagina di risultati di ricerca, piuttosto che seguire il link per cercare di vedere il sito da soli).
Amber è un esempio di sito web che archivia un altro sito non correlato al quale si collega. È anche possibile che i siti web si archivino da soli per garantire la longevità. Nel 2020, Internet Archive ha annunciato una partnership con un’azienda chiamata Cloudflare, utilizzata da siti web popolari o controversi per essere più resistenti agli attacchi denial-of-service condotti da malintenzionati che potrebbero rendere i siti non disponibili a tutti. I siti web che attivano un servizio “sempre online” vedranno i loro contenuti archiviati automaticamente dalla Wayback Machine e, se l’host originale diventa indisponibile per Cloudflare, al suo posto verrà resa disponibile la copia salvata dell’Internet Archive.
Questi approcci funzionano in generale, ma non sempre funzionano in modo specifico. Quando un parere giudiziario, un articolo scientifico o un editoriale indicano un sito o una pagina, l’autore tende ad avere in mente qualcosa di ben preciso. Se quella pagina sta cambiando – e non c’è modo di sapere se cambierà – una citazione a una pagina del 2021 non è affidabile se la copia più vicina di quella pagina è archiviata nel 2017 o nel 2024.
Ispirandomi al lavoro di Brewster e collaborando con Internet Archive, ho lavorato con i ricercatori del Library Innovation Lab di Harvard per dare vita a Perma. Perma è un’alleanza di oltre 150 biblioteche. Gli autori di documenti duraturi – tra cui saggi, articoli di giornale e pareri giudiziari – possono chiedere a Perma di convertire i link contenuti in documenti permanenti archiviati su http://perma.cc; le biblioteche che partecipano trattano le istantanee di ciò che si trova in questi link come accessioni alle loro collezioni e si impegnano a conservarle a tempo indeterminato.

Un’infrastruttura tecnica che consenta agli autori e agli editori di preservare i collegamenti a cui attingono è un inizio necessario. Ma il problema della malleabilità digitale va oltre la tecnica. La legge dovrebbe esitare prima di permettere che la portata dei rimedi per le presunte violazioni dei diritti – siano essi economici come il diritto d’autore o più personali e dignitosi come la diffamazione – si espanda naturalmente man mano che aumenta la facilità di modificare ciò che è già stato pubblicato.
A loro volta, i ricercatori Martin Klein, Shawn Jones, Herbert Van de Sompel e Michael Nelson hanno messo a punto un servizio chiamato Robustify, che consente di incorporare gli archivi di link provenienti da qualsiasi fonte, compreso Perma, in nuovi link “a doppio scopo”, in modo che possano puntare a una pagina che funziona al momento, offrendo al contempo un’alternativa archiviata se la pagina originale fallisce. In questo modo si potrebbe creare un elenco continuo di istantanee di link provenienti da una varietà di archivi, una storia in rete distribuita in modo prudente, in stile Internet, e al tempo stesso gestita dalle istituzioni di lunga data che sono esistite per questo scopo vitale di interesse pubblico: le biblioteche.
Il risarcimento del danno, o l’aggiunta di materiale correttivo, dovrebbero essere favoriti rispetto a una tranquilla modifica retroattiva. E gli editori dovrebbero stabilire politiche chiare e di principio per evitare di intraprendere tali modifiche sotto la pressione del pubblico che non è in grado di accertare una violazione legale (e, in molti casi, gli editori dovrebbero anche resistere alle pressioni legali). (E, in molti casi, gli editori dovrebbero anche opporsi alle pressioni legali).
Il vantaggio di una correzione retroattiva in alcuni casi – si pensi alla correzione di un errore tipografico nelle proporzioni di una ricetta, o al blocco del numero di telefono di qualcuno condiviso a scopo di molestie – deve essere contestualizzato rispetto alla prospettiva di richieste sistemiche e croniche di revisioni da parte di persone o aziende che chiedono modifiche con la sola intenzione di intaccare la documentazione pubblica. L’interesse del pubblico a vedere cosa è cambiato – o almeno a sapere che è stato fatto un cambiamento e perché – è tanto legittimo quanto diffuso. E poiché è diffuso, poche persone sono naturalmente in grado di parlare a suo nome.
Nei casi in cui la censura è considerata la strada giusta, si dovrebbero tenere registrazioni meticolose di ciò che è stato modificato. Tali registri dovrebbero essere disponibili al pubblico, come lo sono i registri di Lumen relativi alle rimozioni di copyright nella ricerca di Google, a meno che tale disponibilità non vanifichi lo scopo dell’elisione. Ad esempio, a tutt’oggi Google non comunica a Lumen quando rimuove una voce negativa in una ricerca sul web relativa a qualcuno che ha invocato il “diritto all’oblio” europeo, per evitare che il pubblico si limiti a consultare Lumen per vedere proprio il materiale che, secondo la legge europea, è stato giudicato un indebito freno alla reputazione di qualcuno (a fronte del diritto del pubblico di sapere).
In questi casi, dovrebbe esistere un mezzo di archiviazione che, pur non essendo disponibile al pubblico in pochi clic, dovrebbe essere a disposizione dei ricercatori che vogliono comprendere le dinamiche della censura online. John Bowers, Elaine Sedenberg e io abbiamo descritto come ciò potrebbe funzionare, suggerendo che le biblioteche possono nuovamente fungere da archivi semichiusi delle azioni censorie online sia pubbliche che private. Possiamo costruire quello che i tedeschi chiamavano un giftschrank, un “armadio dei veleni” contenente opere pericolose che tuttavia dovrebbero essere conservate e accessibili in determinate circostanze. (L’arte imita la vita: C’è una “sezione riservata” nell’universo di Harry Potter e una “stanza dei veleni“, giustamente chiamata, nell’adattamento televisivo di The Magicians).
È davvero allettante coprire gli errori facendo finta che non siano mai accaduti. La nostra tecnologia oggi lo rende allarmantemente semplice, e noi dovremmo aggiungere un po’ di efficienza in meno, un po’ di inerzia in più che in precedenza si è dimostrata di grande qualità a causa della natura dei testi stampati. Persino la Corte Suprema non si è risparmiata qualche ritocco retroattivo alle imprecisioni dei suoi decreti. Come ha detto il professore di diritto Jeffrey Fisher dopo che il nostro collega Richard Lazarus ha scoperto le modifiche, “nei pareri della Corte Suprema, ogni parola è importante… Quando cambiano il testo dei pareri, in pratica stanno riscrivendo la legge”.
Su una scala incommensurabilmente più modesta, se questo articolo contiene un errore, dovremmo tutti volere una nota dell’autore o del redattore in fondo che indichi dove è stata applicata una correzione e perché, piuttosto che questo tipo di revisione silenziosa. (Almeno, io lo voglio prima di sapere quanto possa essere imbarazzante l’errore, ed è per questo che elaboriamo sistemi basati su principi, piuttosto che cercare di orientarci sul momento).
La società non può capire se stessa se non è onesta con se stessa, e non può essere onesta con se stessa se può vivere solo nel momento presente. È da tempo necessario affermare e attuare le politiche e le tecnologie che ci permetteranno di vedere dove siamo stati, anche e soprattutto dove abbiamo sbagliato, in modo da avere un senso coerente di dove siamo e dove vogliamo andare.
Jonathan Zittrain
Fonte: theatlantic.com & DeepWeb



SOSTIENICI TRAMITE BONIFICO:
IBAN: IT19B0306967684510332613282
INTESTATO A: Marco Stella (Toba60)
SWIFT: BCITITMM
CAUSALE: DONAZIONE



