

Il Codice Genetico (DNA) Spiegato Nei Dettagli che Cambierà il tuo Modo di Concepire la Vita
Chi si è vaccinato sappia che è del tutto inutile che legga questo articolo perché non lo riguarda minimamente in quanto la sua sequenza genetica delegata a chi si è sostituito a Dio ha preso una direzione al momento sconosciuta agli scienziati che si sono prodigati nella stesura di questo editoriale.
Toba60
Il nostro lavoro come ai tempi dell’inquisizione è diventato attualmente assai difficile e pericoloso, ci sosteniamo in prevalenza grazie alle vostre donazioni volontarie mensili e possiamo proseguire solo grazie a queste, contribuire è facile, basta inserire le vostre coordinate già preimpostate all’interno dei moduli all’interno degli editoriali e digitare un importo sulla base della vostra disponibilità. Se apprezzate quello che facciamo, fate in modo che possiamo continuare a farlo sostenendoci oggi stesso…
Non delegate ad altri quello che potete fare anche voi.
Staff Toba60
Meno dello 0,1% dei nostri lettori ci supporta, ma se ognuno di voi che legge questo ci supportasse, oggi potremmo espanderci e andare avanti per un altro anno.

Il Tuo codice Genetico come nessuno te lo ha mai fatto conoscere
INTRODUZIONE
Nel numero di marzo 1995 di “Scientific American”, nell’articolo intitolato “Talking Trash” (vedi sotto), gli scienziati affermano di aver trovato modelli di “parole” nel DNA “spazzatura” dell’uomo. Sembra che questo DNA spazzatura (segmenti del genoma del DNA che non codificano istruzioni per la produzione di proteine) presenti gli stessi schemi statistici che si trovano nelle lingue scritte.
Dalla scoperta della molecola a doppia elica del DNA, a metà degli anni ’50, gli scienziati hanno utilizzato il “linguaggio” come metafora per comprendere le strutture e i processi che esprimono la vita a livello biochimico.

Talking Trash: cosa c’è in una parola?
Cosa c’è in una parola? Diversi nucleotidi, direbbero alcuni ricercatori. Applicando metodi statistici sviluppati dai linguisti, i ricercatori hanno scoperto che le parti “spazzatura” dei genomi di molti organismi potrebbero esprimere un linguaggio. Queste regioni sono state tradizionalmente considerate come accumuli “inutili” di materiale frutto di milioni di anni di evoluzione.
La sensazione è che ci sia qualcosa nelle regioni non codificanti”, afferma Eugene Stanley, fisico dell’Università di Boston.
Il nome DNA spazzatura deriva dal fatto che i nucleotidi (i pezzi fondamentali del DNA, combinati nelle cosiddette coppie di basi) non codificano le istruzioni per la creazione di proteine, la base della vita. In effetti, la stragrande maggioranza del materiale genetico negli organismi, dai batteri ai mammiferi, è costituita da segmenti di DNA non codificante, che sono intercalati alle parti codificanti. Negli esseri umani, circa il 97% del genoma è spazzatura. Negli ultimi 10 anni i biologi hanno iniziato a sospettare che questa caratteristica non sia del tutto banale.
“È improbabile che ogni coppia di basi del DNA non codificante sia critica, ma è anche sciocco dire che è tutta spazzatura”, osserva Robert Tjian, biochimico dell’Università della California a Berkeley.
Per esempio, alcuni studi hanno scoperto che le mutazioni in alcune parti delle regioni non codificanti portano al cancro. I fisici hanno confermato i sospetti qualche anno fa, quando chi studiava i frattali ha notato alcuni schemi nel DNA spazzatura. Hanno scoperto che le sequenze non codificanti presentano le cosiddette correlazioni a lungo raggio. Cioè, la posizione di un nucleotide dipende in qualche misura dalla posizione di altri nucleotidi.
I loro schemi seguono una proprietà simile a quella dei frattali, chiamata rumore 1/f, che è insita in molti sistemi fisici che si evolvono nel tempo, come i circuiti elettronici, la periodicità dei terremoti e persino i modelli di traffico. Nel genoma, tuttavia, le correlazioni a lungo raggio si verificavano solo per le sequenze non codificanti; le parti codificanti mostravano un modello non correlato. Questi segnali suggerivano che il DNA spazzatura potesse contenere un qualche tipo di informazione organizzata. Per decifrare il messaggio, Stanley e i suoi colleghi Rosario N. Mantegna, Sergey V. Buldyrev e Shlomo Haviin hanno collaborato con Amy L Goldberg, Chung-Kang Peng e Michael Simons della Harvard Medical School.
Hanno preso spunto dal lavoro del linguista George K. Zipf che, esaminando i testi di diverse lingue, ha classificato la frequenza con cui le parole ricorrono. Tracciando la classifica delle parole rispetto a quelle presenti in un testo si ottiene una relazione distinta. La parola più comune “the” in inglese ricorre 10 volte più spesso della decima parola più comune, 100 volte più spesso della centesima parola più comune e così via. I ricercatori hanno testato la relazione su 40 sequenze di DNA di specie che vanno dai virus agli esseri umani.
Hanno quindi raggruppato coppie di nucleotidi per creare parole lunghe da tre a otto coppie (ci vogliono tre coppie per specificare un amminoacido). In tutti i casi, hanno scoperto che le regioni non codificanti seguivano la relazione Zipf più da vicino rispetto alle regioni codificanti, suggerendo che il DNA spazzatura segue la struttura delle lingue.
“Non ci aspettavamo che il DNA codificante obbedisse a Zipf”, osserva Stanley. “Un codice letterale uno se via terra, due se via mare”.
Non ci possono essere errori in un codice. Il linguaggio, invece, è un sistema statistico e strutturato con ridondanze incorporate. Qualche parola borbottata o qualche errore di battitura sparso di solito non rendono incomprensibile una frase.
In realtà, i ricercatori hanno testato questa nozione di ripetizione applicando una seconda analisi, questa volta del teorico dell’informazione Claude E Shanon, che negli anni ’50 ha quantificato le ridondanze nelle lingue. Hanno scoperto che il DNA spazzatura contiene da tre a quattro volte le ridondanze dei segmenti di codifica. A causa della natura statistica dei risultati, i ricercatori ammettono che è improbabile che le loro scoperte aiutino i biologi a identificare gli aspetti funzionali del DNA spazzatura. Piuttosto, il lavoro potrebbe indicare qualcosa sull’immagazzinamento efficiente delle informazioni.
“Ci deve essere una sorta di disposizione gerarchica delle informazioni per permettere di usarle in modo efficiente e di avere una certa adattabilità e flessibilità”, osserva Goldberger.
Un’altra ipotesi è che le quenze possano essere essenziali per il modo in cui il DNA deve ripiegarsi per adattarsi al nucleo.

Alcuni ricercatori dubitano che il gruppo abbia scoperto qualcosa di significativo. Uno di questi è Beniot Mandelbrot dell’Università di Yale. Negli anni ’50 il matematico ha sottolineato che la legge di Zipf è un gioco di numeri statistici che ha poco a che fare con le caratteristiche riconoscibili del linguaggio, come la semantica. Inoltre, sostiene che il gruppo ha commesso diversi errori.
Le loro prove non stabiliscono nemmeno lontanamente la legge di Zipf”, afferma.
Ma queste critiche non impediscono ai ricercatori di Boston di cercare di decifrare la lingua del DNA spazzatura.
Potrebbe essere una lingua morta”, dice Stanley, “ma la ricerca sarà entusiasmante”.
Le ricerche attuali sembrano indicare che la metafora potrebbe essere più letterale di quanto si pensasse. Supponiamo che ci siano tratti di DNA incorporati nel genoma dell’uomo che, se adeguatamente “decodificati”, ci parlano in una lingua umana. Quale sarebbe questa lingua e cosa direbbe? Il mio lavoro indica la possibilità che la lingua sia l’ebraico o, forse, un precursore protocaanita della lingua ebraica.
Il mio lavoro esamina alcune delle prove a sostegno di questa ipotesi. Lo riporto qui nella speranza che possa stimolare la discussione e ulteriori ricerche. Per leggerlo e “giocarci” è necessario addentrarsi in quelle che molti considerano categorie di conoscenza reciprocamente esclusive: la scienza e l'”occulto”. Pochissime persone saranno in grado o disposte ad accettare l’idea che queste due arene antitetiche del sapere possano illuminarsi a vicenda. Spero di trovare alcune persone in grado di farlo.
Alcuni anni fa mi sono imbattuto in una singolare somiglianza di forma tra il codice genetico e una fusione dell’alfabeto ebraico con l’antico sistema divinatorio cinese dell’I Ching, o “Libro dei Mutamenti”. Stavo studiando l’I Ching quando mi sono imbattuto in un libro che dimostrava un isomorfismo tra i 64 simboli dell’I Ching (chiamati esagrammi o kua) e i 64 codoni del codice genetico. Mi sono chiesto se tra i sistemi mistici o occulti di altre culture potesse esistere un insieme di simboli corrispondenti agli aminoacidi del codice genetico per i quali sono codificati i 64 codoni. Mi sono rivolto al sistema occulto ebraico della Qabalah e ho scoperto il Sefer Yetzirah o “Libro della Creazione“.
Il Sefer Yetzirah è il primo testo conosciuto della Qabalah. Il suo scopo “magico” è quello di educare il lettore al processo di creazione utilizzando l’alfabeto ebraico come ha fatto il Creatore. Poiché alle 22 carte da briscola (chiamate anche atu) del sistema divinatorio dei Tarocchi sono assegnate lettere ebraiche, ho pensato che forse avrei potuto confrontare i simboli, le immagini e i concetti delle carte da briscola dei Tarocchi con i corrispondenti contenuti dell’I Ching kua. Poi, se ci sono abbastanza somiglianze, potrei assegnare ogni briscola a un gruppo di I Ching kua. Il risultato sarebbe l’assegnazione di una lettera ebraica per ogni aminoacido e codone di punteggiatura del codice genetico.

Grafico 1
I codoni per gli amminoacidi letti da sinistra-in alto-destra.
Rosso=punteggiatura
Bianco=Apolare
Blu=Amminoacidi polari.
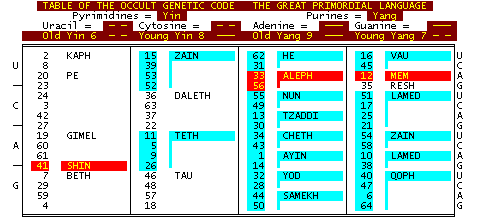
I numeri di capitolo di Ching kua sono assegnati ai codoni e lettere ebraiche agli amminoacidi.
Rosso=’Madre’
Bianco=’Doppio’
Blu=Lettere ebraiche ‘semplici’.
L’assegnazione dei simboli dell’I Ching agli acidi nucleici del codice genetico si basa sulla somiglianza di forma e funzione tra i rispettivi domini di conoscenza. L’assegnazione delle lettere ebraiche ai gruppi di kua dell’I Ching si basa sulla somiglianza di contenuto tra gli atu dei Tarocchi e i kua dell’I Ching. La lettera ebraica PE, sull’atu dei Tarocchi “La Torre”, è assegnata ai kua 20, 23, 24, 3, 42 e 27 dell’I Ching perché il simbolo, l’immagine e il concetto contenuti nell’atu e nel kua sono molto simili. Di conseguenza, il PE è analogo all’aminoacido leucina perché i kua assegnati sono analoghi ai codoni che codificano per la leucina.
Ho utilizzato la traduzione dell’I Ching di Wilhelm/Baynes e il “Libro di Thoth” di Aleister Crowley, la sua interpretazione dei Tarocchi. Non pensavo che avrei trovato una grande somiglianza tra questi due sistemi di divinazione, dato che l’I Ching di Wilhem deriva dalla scuola di filosofia orientale confuciana, molto moralista, mentre i Tarocchi di Crowley sono un veicolo per il suo sistema altamente idiosincratico e minimamente moralista di “magia sessuale” come via per l’illuminazione.
Immaginate il mio shock e la mia sorpresa quando ho scoperto che questi due diversi approcci alla divinazione, uno orientale e l’altro occidentale, mostravano un’enorme somiglianza di contenuti; simbolici, immaginari e concettuali Quando raggruppati e disposti come gli acidi nucleici e gli aminoacidi sono raggruppati e disposti nel codice genetico.
Non riuscivo a togliermi dalla testa l’idea che questi due sistemi di simboli potessero essere veicoli per il trasporto di due metà di quello che potrebbe essere un virus testuale, destinato a infettare il corpo politico della Terra in un momento in cui la conoscenza è necessaria. Forse da qualche parte nella vasta biblioteca genetica che è il genoma umano c’è un chiaro messaggio, in ebraico o in una lingua precursore, da parte del “Creatore/i”.
Se “il Creatore” ha un senso dell’umorismo simile al nostro, forse si divertirebbe all’idea di farci sapere, in un momento futuro in cui saremo tecnologicamente abbastanza avanzati, chi siamo e come siamo nati.
Come vengono assegnati gli esagrammi (kua). Ai codoni del codice genetico
Ci sono 64 esagrammi (kua) nell’I Ching e ci sono 64 codoni nel codice genetico universale. Il kua può essere pensato come composto da 3 simboli di 2 linee ciascuno. I codoni sono composti di 4 acidi nucleici presi 3 alla volta. Il problema è: quale acido nucleico corrisponde a quale Simbolo I Ching?
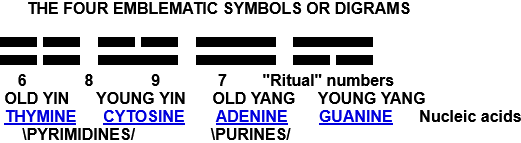
I quattro simboli o digrammi emblematici
Vecchio Ying

Giovane Ying

Vecchio Yang

Giovane Yang
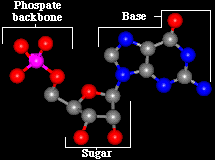
Si noti che la struttura di base degli acidi nucleici pirimidinici ha 6 atomi e quella degli acidi nucleici purinici ne ha 9. Il simbolo Vecchio Yang ha un “numero rituale” di 9 e il numero rituale del Vecchio Yin è 6. Pertanto assegno i simboli yang alle purine e i simboli yin alle pirimidine.
La cosa successiva da determinare è: quale simbolo yang (Vecchio o Giovane) corrisponde a quale acido nucleico purinico (Adenina o Guanina).
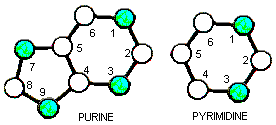
Nell’I Ching, lo yang è associato all’energia e lo yin alla materia. L’energia per tutti i processi biochimici della cellula è fornita dalla sostanza chimica Adenosina Trifosfato. Il suo componente principale è, ovviamente, l’acido nucleico Adenina. Poiché yang=energia e l’adenina è associata alla produzione di energia cellulare, assegno l’adenina all’Antico Yang perché ha due linee yang. A causa del modo in cui gli acidi nucleici si legano l’uno all’altro nella molecola a doppia elica del DNA, l’assegnazione degli altri acidi nucleici ai simboli segue logicamente questa prima assegnazione.
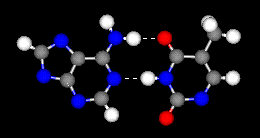
L’adenina si lega alla timina con 2 atomi di idrogeno
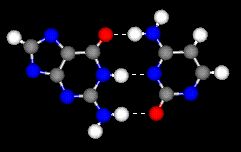
La guanina si lega alla citosina con 3 atomi di idrogeno
Il Vecchio Yin è l’opposto complementare del Vecchio Yang. Nella doppia elica del DNA la Timina è sempre opposta all’Adenina, quindi è assegnata al Vecchio Yin. (Nota: l’acido nucleico Uracile sostituisce la Timina nell’RNA messaggero [mRNA]).
Nella doppia elica del DNA la Guanina è sempre opposta alla Citosina. Poiché la guanina è già assegnata allo Yang giovane (perché è un acido nucleico purinico), la citosina deve essere assegnata allo Yin giovane.
Interpretazione “sefer yetzirah” attraverso l’ingegneria genetica
L’interpretazione principale che ho utilizzato è: “Understanding Jewish Mysticism: A Source Reader” di David R. Blumenthal (qui indicato come UJM).
L’I Ching, il primo testo cinese di pensiero speculativo sistematico, fornisce la fonte di una profonda analogia con i 64 codoni del codice genetico. La sua controparte ebraica è il Sefer Yetzirah. Esso fornisce la fonte per l’altra metà del codice genetico occulto: i 20 aminoacidi e i 2 gruppi di codoni di stop.
Il Sefer Yetzirah è la prima opera conosciuta del pensiero magico ebraico inclusa nella materia nota come Kabbalah o Qabala. Il suo titolo si traduce in inglese come “Book of Creation”. Fu scritto tra il terzo e il sesto secolo. È estremamente breve, meno di 2000 parole, ed è scritto in uno stile terso ed enigmatico che ha sfidato tutti i tentativi di chiarirne completamente il significato.
In breve, il testo racconta come il Creatore abbia usato i numeri da 1 a 10 e le 22 lettere dell’alfabeto ebraico per creare l’Universo e tutti gli esseri viventi che lo compongono. Le lettere ebraiche sono modellate come pezzi di argilla, poste una di fronte all’altra e manipolate in altro modo per creare, in modo magico, tutto ciò che esiste.
Il Sefer Yetzirah interpreta il “discorso” di Dio in modo molto chiaro. Dio non ha parlato a se stesso, come un monarca assoluto che vuole ed è fatto. Piuttosto, ha generato sostanza, da cui ha formato lettere, da cui ha combinato “parole”, che sono diventate cose. Il “discorso” di Dio non era un suono, ma una modellazione di unità di argilla”. (UJM p. 46)
“… l’autore (del Sefer Yetzirah) sostiene che, utilizzando la sua interpretazione, si può diventare a propria volta un “creatore”, anche se su scala molto più ridotta. In altre parole, il Sefer Yetzirah propone non solo un’interpretazione di “In principio”, ma anche un insegnamento segreto di magia creativa. Insegna, propriamente inteso, il segreto della Creazione e del creato, del Creatore e dell’artefice”. (UJM p. 9)
“… al lettore viene detto “prova” ed “esplora” (e in alcuni manoscritti anche “conosci, calcola e forma”) – cioè di cercare di combinare lettere e numeri e di “creare” come ha fatto Dio. Tale attività era infatti nota nel giudaismo della tarda antichità. Si dice che alcuni rabbini fossero in grado di creare piccoli animali e homunculi (uomini di argilla animati, che però non possono parlare)”. (UJM p. 16)
“… al termine di un profondo studio dei misteri del Sefer Yetzirah sulla costruzione del cosmo, i saggi (come Abramo il Patriarca) acquisirono il potere di creare esseri viventi”. (“Kabballah”, Gershom Scholem, Meridian Books, 1974, p. 352)

“Quando Abramo nostro padre, che riposi in pace, arrivò: guardò, vide, capì, esplorò, incise, sbozzò e riuscì nella Creazione, come è detto: ‘E i corpi che avevano fatto a Haran’ [Genesi 12:5]”. (UJM p. 43)
“Il Talmud, il grande compendio della letteratura rabbinica, riporta molti casi di magia praticata dai rabbini. Un esempio deve bastare:
Quale [magia] è del tutto permessa?
Come quella di R. Hanina e R. ‘Oshaia, che passavano ogni sabato a studiare le Leggi della Creazione, per mezzo delle quali crearono un vitello di terza età e lo mangiarono”. Talmud, Sanhedrin 67a, citato in J. Neusner, There We Sat Down (New York e Nashville: Abingdon Press, 1972), p. 80.
“E questo è il segno: Egli guarda e parla, e fa tutto ciò che è formato e tutto ciò che è parlato con un unico termine. E il segno della cosa è ventidue bisogni in un solo corpo”. (UJM p. 26)
“… I ventidue bisogni del corpo non sono specificati, anche se, qualunque cosa siano, corrispondono alle ventidue lettere dell’alfabeto”. (UJM p. 26)
“In tutto il Sefer Yetzirah, la parola per “corpo” è nefesh, che di solito viene tradotta come “anima”. Tuttavia, il contesto qui e alla fine del libro richiede ‘corpo’”. (UJM p. 32)
Quindi, nel Sefer Yetzirah, abbiamo un testo magico che pretende di permettere a chi lo comprende e lo usa di creare creature viventi. Ciò avviene utilizzando 22 lettere che vengono manipolate come pezzi di argilla in catene che sono disposte in paralleli complementari e altre forme. Questo è molto simile alle descrizioni scientifiche dell’attività che si svolge all’interno delle cellule degli esseri viventi. Gli scienziati usano il linguaggio della metafora per descrivere queste sostanze chimiche e le loro attività. Le lunghezze del DNA e i geni che vi risiedono sono chiamati frasi genetiche e i loro componenti chimici sono chiamati parole e lettere. Contando i codoni di stop come 2 gruppi separati, ci sono 22 lettere di amminoacidi nell’alfabeto chimico della vita.
“2. Ventidue lettere sono il fondamento: Egli le ha incise, le ha sbozzate, le ha combinate, le ha pesate, le ha poste agli opposti e attraverso di esse ha formato tutto ciò che è formato e tutto ciò che è destinato ad essere formato.” (UJM p. 21)
Oltre alle analogie numeriche e funzionali tra gli amminoacidi e l’alfabeto ebraico, esiste anche una coincidenza di categoria. Le lettere della lingua ebraica nel Sefer Yetzirah sono disposte in 3 categorie.
3 lettere “madri”: Aleph, Mem, Shin
7 lettere “doppie”: Beth, Gimel, Daleth, Kaph, Pe, Resh, Tau
12 lettere “semplici”: He, Vau, Zain, Cheth, Teth, Yod, Lamed, Nun,
Samekh, Ayin, Tzaddi, Qoph
Gli aminoacidi e i codoni di punteggiatura hanno molte proprietà chimiche con cui possono essere classificati, ma la proprietà più semplice descrive il loro comportamento nell’ambiente acquoso della cellula. Gli amminoacidi possono essere descritti come idrofobici (odiano l’acqua) o idrofili (amano l’acqua).
12 aminoacidi sono idrofili: Serina, Treonina, Tirosina, Istidina,
Glutammina, Cisteina, Asparagina, Arginina, Aspartato, Glutammato,
Lisina, Glicina
8 amminoacidi sono idrofobici: Valina, Isoleucina, Prolina, Leucina
Fenilalanina, Triptofano, Alanina, Metionina
Poiché la metionina serve anche a segnare il punto di partenza della traduzione sul filamento di mRNA, l’ho inserita nella categoria “Punteggiatura” insieme ai 2 gruppi di codoni di stop. Pertanto, i 64 codoni del codice genetico, quelli che codificano per gli amminoacidi e quelli che fungono da “punteggiatura” (inizio e fine), possono essere inseriti nello stesso numero di categorie con lo stesso numero di elementi in ciascuna, come le lettere dell’alfabeto ebraico.
3 gruppi di punteggiatura (2 gruppi di stop, 1 gruppo di start [metionina])
7 Aminoacidi idrofobici
12 Aminoacidi idrofili
Questa curiosa coincidenza di categorie simili si è rivelata molto utile quando si è trattato di abbinare le singole lettere ebraiche agli amminoacidi corrispondenti.
Quando gli scienziati parlano della chimica della vita, usano spesso la metafora del linguaggio, come già sottolineato in precedenza. Utilizzano anche altre metafore. Anche i filamenti di DNA o di mRNA vengono definiti “fili” e l’intero genoma viene spesso definito “il filo della vita”. Ne parlo perché una delle tante traduzioni del Sefer Yetzirah che ho letto usa ampiamente la metafora del “filo della vita”.
“Le ventidue lettere che formano la stamina, dopo essere state designate e stabilite da Dio, Egli le ha combinate, pesate e modificate, e con esse ha formato tutti gli esseri che esistono e tutti quelli che saranno formati in ogni tempo a venire.” (p. 20) (The Ancient and Mystical Order Rosae Crucis – AMORC, traduzione del Rev. Dr. Isidor Kalisch, 1877)
La parola che Kalisch traduce con “resistenza” è la parola ebraica yesod che altri traducono (più correttamente) con “fondamento”. Non si sa perché Kalisch abbia scelto “stamina”, ma il suo uso in questo contesto è provocatorio perché deriva dal latino:
STAMINA – plurale di stame = ordito: il filo della vita tessuto dal destino. resistenza. Greco stemon = filo. Si noti che: Stame – l’organo del fiore che produce il gamete maschile. Questo dimostra che il concetto di “filo della vita” è stato legato precocemente al processo di riproduzione.

Quindi, se nel testo sostituiamo l’origine di “stamina” con “stamina”, otteniamo: “Le ventidue lettere che formano il filo della vita, dopo essere state designate e stabilite da Dio, Egli le ha combinate, pesate e modificate, e con esse ha formato tutti gli esseri che esistono e tutti quelli che si formeranno in ogni tempo a venire”.
“Questa Torah, il movimento linguistico dell’Ein-Sof in sé, è chiamata malbush (“veste”), anche se in realtà è inseparabile dalla sostanza divina ed è tessuta al suo interno… (la veste) è composta in lunghezza dagli alfabeti del Sefer Yetzirah e aveva 231 “porte”… che formano l’archistruttura del pensiero divino. La sua larghezza era composta da un’elaborazione del Tetragramma secondo il valore numerico delle quattro possibili grafie dei nomi completamente scritti delle sue lettere, … che erano i “fili” e la “trama” che originariamente si trovavano nell’orlo dell’abito. … La dimensione di questa veste era il doppio della superficie necessaria per la creazione di tutti i mondi. Dopo essere stato tessuto, fu piegato in due: metà di esso saliva e le sue lettere stavano dietro le lettere dell’altra metà”. (Cabala, p. 132)
Vediamo quindi che la tradizione ebraica utilizza le metafore dell’argilla e dei fili per spiegare la creazione di tutti gli esseri viventi, compreso l’uomo. Passiamo ora ai cinesi, il cui I Ching costituisce l’altra metà del codice genetico occulto. Anche loro hanno miti e tradizioni di creazione che utilizzano metafore simili. I seguenti estratti sono tratti da: “Mythologies of the Ancient World”, Samuel Noah Kramer Ed.
Fu Hsi è il leggendario creatore dell’I Ching. Sua sorella/consorte è Nu Kua. Anche lei viene rappresentata come la creatrice dell’umanità:
“Si dice che quando il Cielo e la Terra si erano aperti, ma prima che ci fossero gli esseri umani, Nu Kua creò gli uomini accarezzando insieme la terra gialla. Ma il lavoro impegnava le sue forze e non le lasciava tempo libero, per cui trascinò una corda nel fango, ammucchiandolo per farne degli uomini. Perciò i ricchi e i nobili sono gli uomini di terra gialla, mentre i poveri e gli umili – tutte le persone comuni – sono gli uomini fatti di corda”. (p. 338)
Per concludere l’analisi, mostrerò alcune delle curiose prove derivate dalla pratica qabalistica della gematria, la pratica di assegnare valori numerici alle parole ebraiche basandosi sui valori numerici delle lettere ebraiche. Si noti che nell’uomo normale ci sono 46 cromosomi. Ciascuno dei genitori contribuisce, attraverso lo sperma e l’ovulo, con 23 cromosomi al nuovo essere che creano insieme.
Si noti anche che ognuno dei 64 esagrammi dell’I Ching è composto da 6 righe, per un totale di 384 righe.
(vita 23) + (filo 23) = 46
(padre 4) + (madre 42) = 46
(Adamo 45) + (Eva 19) = 64
(sperma 277) + (ovulo 107) = 384
(maschio 227) + (femmina 157) = 384
Fonti: Archivi Privati & Scientific American








